
爬虫进阶|网页自动化Selenium从入门到实战
一、什么是网页自动化爬虫?为什么需要它?
传统接口爬虫靠模拟API请求获取数据,遇到验证码、JS动态渲染、登录校验、无限滚动等场景极易失效。
网页自动化爬虫:用程序控制真实浏览器,完全模拟人类操作(打开、点击、输入、滚动、等待),能拿到渲染后的完整页面,应对严苛反爬。
适用场景
登录带验证码/滑块验证
数据由JS异步渲染、源码无数据
需滚动/点击加载更多内容
接口加密混淆、难以抓包分析
优缺点速览
✅ 优点:适配复杂交互、获取完整渲染HTML、绕过接口加密
❌ 缺点:资源占用高、速度慢于接口请求、页面改版需维护
二、Selenium环境搭建
Selenium是主流Web自动化工具,支持Python控制Chrome/Firefox等浏览器。
1. 安装依赖
pip install selenium2. 浏览器驱动配置
先确定浏览器的版本号,程序员主流用的浏览器是Chrome,所以这里以Chrome为例,打开路径为是浏览器右上角的 ... -> 设置 -> 关于Chrome。
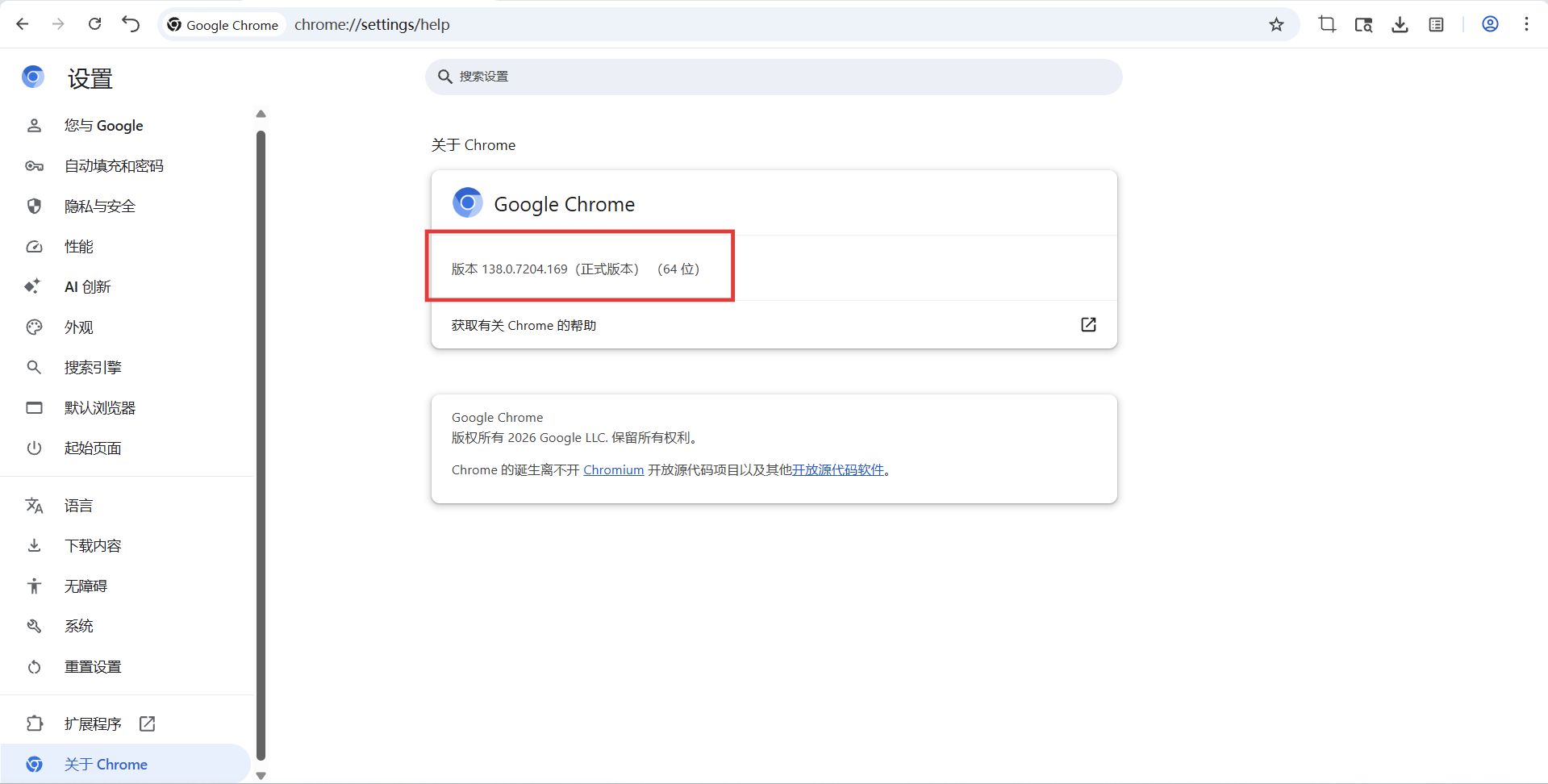
Chrome浏览器的驱动程序可以在https://registry.npmmirror.com/binary.html?path=chrome-for-testing/网站下载(用其他浏览器,可以在搜索引擎里搜索一下关键字,比如“Selenium Firefox浏览器驱动下载”)
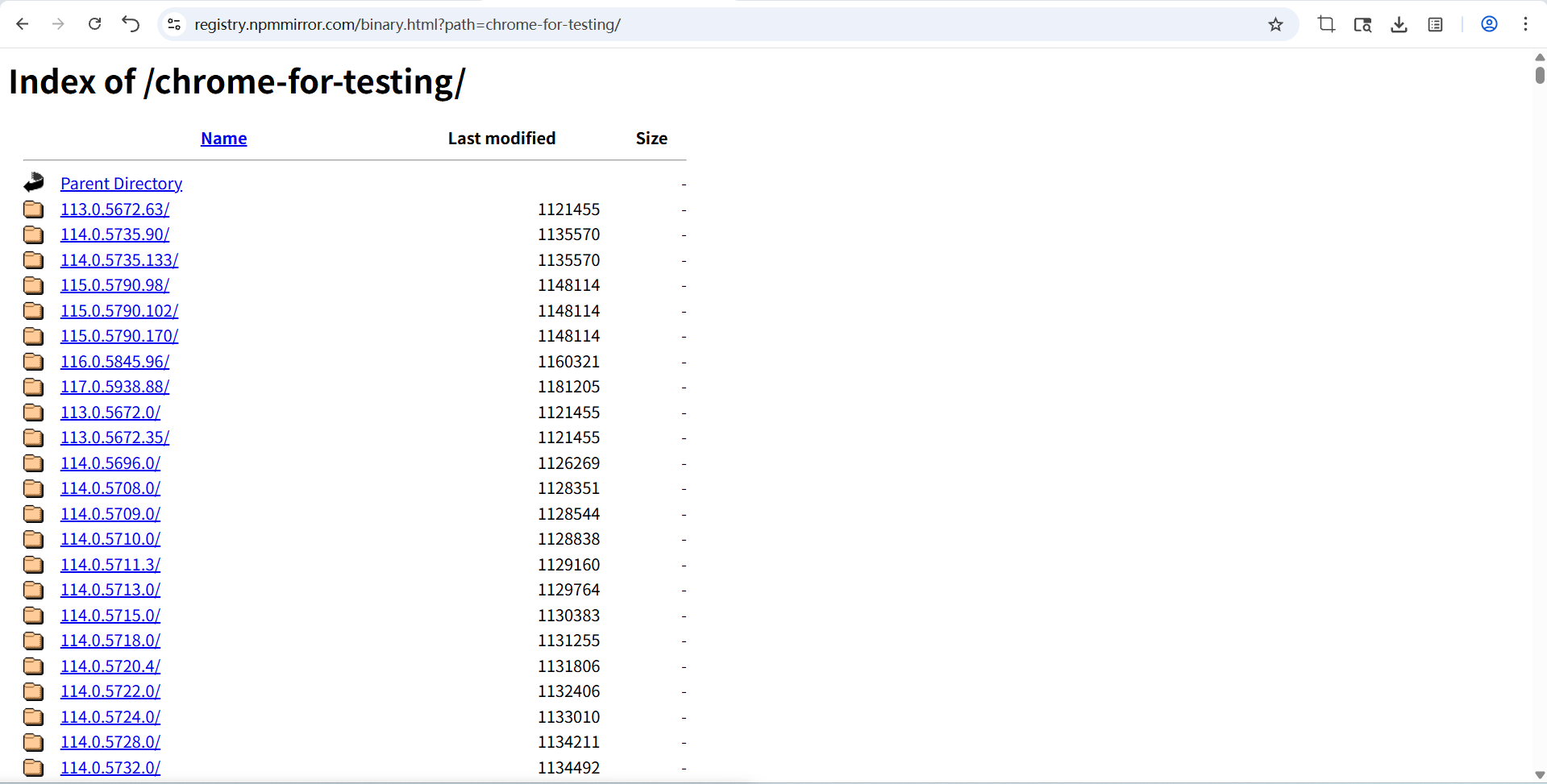
查找自己浏览器版本对应的驱动程序安装文件就可以了。以138.0.7204.169为例子,138为主版本号,0为次版本号,7204修订版本号,101是构建版本号。如果找不到对应到构建版本号的驱动程序,也可以下载和修订版本号匹配的文件,如138.0.7204.~。如果修订版本号也没有匹配的,就找与主版本号和次版本号匹配的,依此类推。
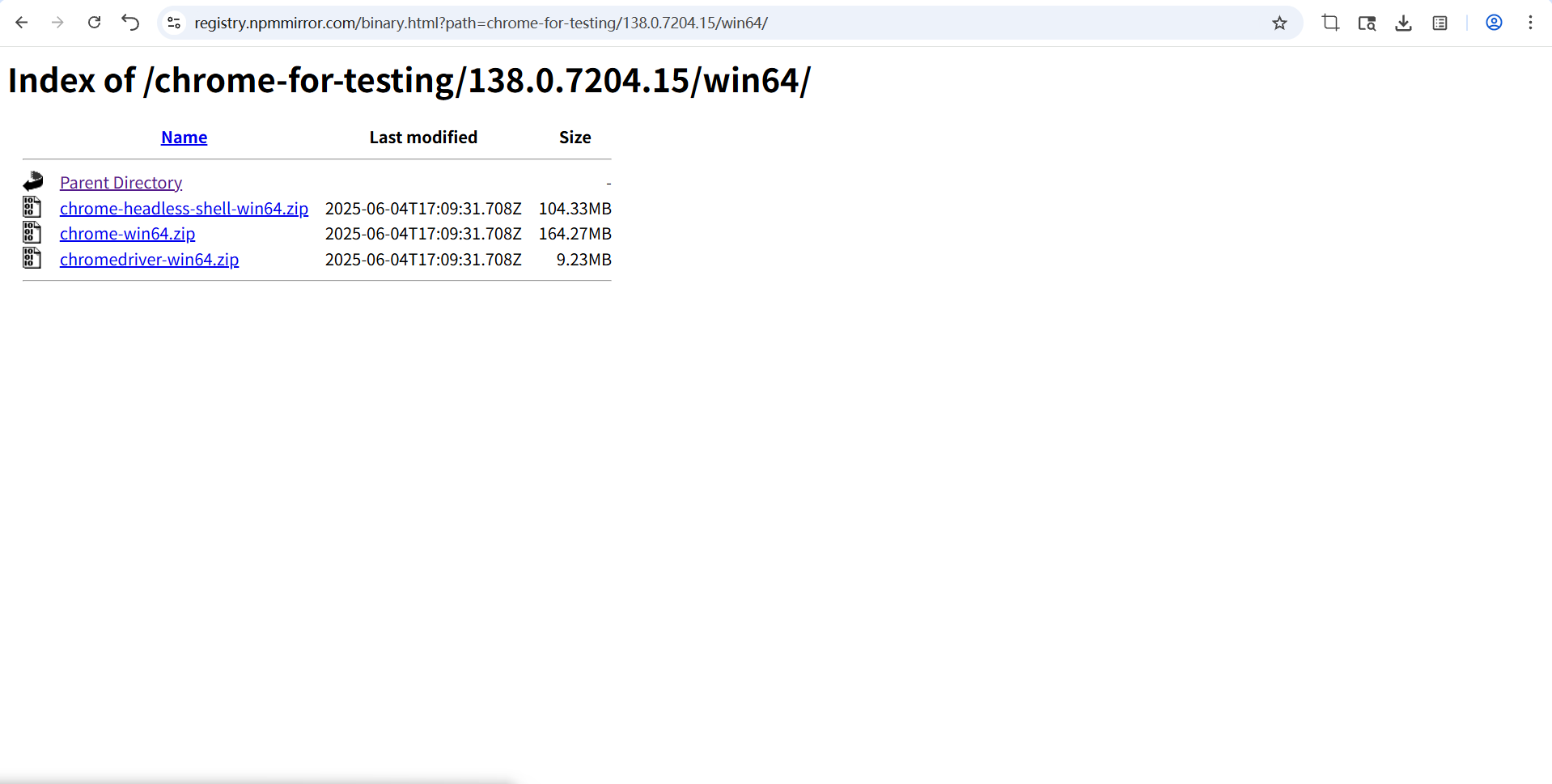
要下载带driver关键字的文件,另外两个并不是咱们所需要的驱动程序。下载好后解压进入到文件夹里,可以看到一个叫“chromedriver”的可执行文件,可以把驱动文件放到某个固定的路径下。
通过python代码来启动Chrome浏览器。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service("D:/SeleniumDriver/chromedriver.exe")
driver = webdriver.Chrome(service=service)如何程序报错,找不到 Chrome(而实际已安装了Chrome),则手动指定 Chrome 位置。
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options # 新增:导入配置项
# 配置 Chrome 选项,指定 Chrome 安装路径
chrome_options = Options()
# TODO:替换成你电脑上 chrome.exe 的实际路径(示例是默认路径,根据自己的改)
chrome_options.binary_location = r"C:\Program Files\Qoom Chrome\chrome.exe"
# 驱动路径(Windows用/或r字符串)
service = Service(r"D:\SeleniumDriver\chromedriver.exe")
driver = webdriver.Chrome(service=service, options=chrome_options)
三、Selenium核心:浏览器基础操作
四个必备模块与类:
使用Selenium编写爬虫时,常用的四个工具是:
webdriver:封装浏览器的操作,例如启动、访问URL、打开新标签页。
By:用于定位网页中的元素(如
By.ID、By.CLASS_NAME)。Keys:模拟键盘操作(如回车键、删除键)。
ActionChains:模拟鼠标动作链(如点击、拖拽)。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains启动浏览器常用操作
1.访问网页
使用get(url)方法访问网页。
使用title属性获取网页标题,使用current_url获取网页地址。
使用
time.sleep()保持浏览器窗口一段时间。from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.chrome.options import Options # 新增:导入配置项 from time # 配置 Chrome 选项,指定 Chrome 安装路径 chrome_options = Options() # TODO:替换成你电脑上 chrome.exe 的实际路径(示例是默认路径,根据自己的改) chrome_options.binary_location = r"C:\Program Files\Qoom Chrome\chrome.exe" # 驱动路径(Windows用/或r字符串) service = Service(r"D:\SeleniumDriver\chromedriver.exe") driver = webdriver.Chrome(service=service, options=chrome_options) driver.get("https://www.douban.com") print(driver.title, driver.current_url) time.sleep(3)
2.最大化浏览器窗口
使用maximize_window()方法让浏览器窗口全屏,以避免后续操作因分辨率不同产生误差。
3.打开新标签页
使用execute_script("window.open('');")在浏览器中打开新标签页,execute_script()括号中为可执行的.js代码。
使用window_handles属性查看所有标签页ID。
4.切换标签页
使用switch_to.window(handle)切换到指定标签页。补充:switch_to获得SwitchTo对象(上下文切换控制器),常用与处理标签页、iframe等上下文的切换。
可以在不同标签页中加载不同页面。
5.关闭标签页
使用close()方法关闭当前活跃的标签页。
若需关闭特定标签页,先切换至该标签页再关闭。
driver.maximize_window() # 最大化浏览器窗口
driver.get("https://www.douban.com") # 打开豆瓣首页
driver.execute_script("window.open('');") # 新建空白标签页
window_handle_list = driver.window_handles # 获取所有标签页句柄
time.sleep(3) # 等待3秒
driver.switch_to.window(window_handle_list[0]) # 切换到第一个标签页
print("切换到第一个标签页")
time.sleep(3) # 等待3秒
driver.switch_to.window(window_handle_list[1]) # 切换到第二个标签页
print("切换到第二个标签页")
driver.get("https://www.baidu.com") # 第二个标签页打开百度
print(f"当前页面标题: {driver.title}") # 打印页面标题
print(f"当前页面URl: {driver.current_url}") # 打印当前页面URL
time.sleep(3) # 等待3秒
driver.switch_to.window(window_handle_list[1]) # 切换到第二个标签页
driver.close() # 关闭当前标签页
print("第一个标签页已关闭")
time.sleep(5) # 等待5秒后程序继续四、用Selenium获取静态网页数据(By类)
查找元素
使用 find_element 查找单个元素,找不到会报错。建议使用try...except 避免因找不到元素而报错。
# 找 1 个元素
item = driver.find_element(By.CLASS_NAME, "title")
# 推荐加 try except
try:
item = driver.find_element(By.ID, "no_id")
except:
print("元素没找到")使用 find_elements 批量查找元素,找不到会返回空列表。
# 找多个元素
item_list = driver.find_elements(By.TAG_NAME, "div")
item = item_list[0].text if len(item_list) >= 1 else None获取元素文本
使用 element.text 获取文本内容。
element = driver.find_element(By.ID, "name")
text = element.text # 获取元素里的文字
print(text)获取元素的属性值
使用 get_attribute("属性名") 获取指定属性的值。
link = driver.find_element(By.TAG_NAME, "a")
href = link.get_attribute("href") # 获取链接地址
src = link.get_attribute("id") # 获取id获取元素HTML
get_attribute("outerHTML") 获取完整HTML,包括自身标签,子元素、文本、注释等。
get_attribute("innerHTML") 获取内部HTML,不含自身标签,仅含子元素、文本、注释等。
element = driver.find_element(By.ID, "box")
# 包含自己标签的完整 HTML
outer = element.get_attribute("outerHTML")
# 只包含内部内容,不带自己标签
inner = element.get_attribute("innerHTML")查找属于多个类的元素
By.CLASS_NAME不支持多个类名。
可使用 By.CSS_SELECTOR 并传入组合选择器 .类1.类2。格式:.find_element(By.CSS_SELECTOR,"表达式")
# 不支持:By.CLASS_NAME("a b")
# 正确写法:CSS选择器 .类1.类2
element = driver.find_element(By.CSS_SELECTOR, ".item.active.red")使用XPath查找元素
By.XPATH 可快速定位深层嵌套的元素。格式:.find_element(By.XPATH,"表达式")
# 找 div 下 class 为 title 的 span
element = driver.find_element(
By.XPATH,
"//div[@class='box']/span[@class='title']"
)模糊查找元素
使用 By.CSS_SELECTOR(CSS 选择器)支持模糊匹配。格式:.find_element(By.CSS_SELECTOR,"表达式")
语法规则:
包含子字符串: [属性名*="值"]
以某字符串开头: [属性名^="值"]
以某字符串结尾: [属性名$="值"]
# 包含 "btn" 字符串
driver.find_element(By.CSS_SELECTOR, "[class*='btn']")
# 以 "head" 开头
driver.find_element(By.CSS_SELECTOR, "[id^='head']")
# 以 "img" 结尾
driver.find_element(By.CSS_SELECTOR, "[src$='.img']")五、用Selenium获取动态网页数据
动态网页的挑战
静态网页:HTML源码里直接包含数据。
动态网页:HTML源码中没有目标数据,需要等待页面加载完成才能获取。
方法1:固定时间等待
最简单的方式是调用 time.sleep(N) 让程序暂停几秒,等待页面完成加载。
方法2:隐式等待
使用 driver.implicitly_wait(N) 设置全局等待时间。
在查找元素时,如果元素存在-->找出元素-->执行下一步,如果元素不存在-->在指定时间内重复查找-->(直到出现或超时)
方法3:显式等待
显式等待更灵活,可以为特定操作单独设置等待条件。
需要用到 WebDriverWait 和 expected_conditions函数(常简写为 EC)。
常用条件:
隐式等待与显示等待具体区别
三种方法对比
固定时间等待:简单直观,但效率低。
隐式等待:自动应用于所有元素查找,适合简单场景。
显式等待:灵活可控,适合复杂场景和动态网页。
案例演示
以前程无忧这个网站演示。
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options # 新增:导入配置项
# 配置 Chrome 选项,指定 Chrome 安装路径
chrome_options = Options()
# TODO:替换成你电脑上 chrome.exe 的实际路径(示例是默认路径,根据自己的改)
chrome_options.binary_location = r"C:\Program Files\Qoom Chrome\chrome.exe"
# TODO:替换成你电脑上驱动文件的路径
service = Service(r"D:\SeleniumDriver\chromedriver.exe")
driver = webdriver.Chrome(service=service, options=chrome_options)
driver.maximize_window() #最大化浏览器窗口
driver.get("https://we.51job.com/pc/search")
start = time.time()
# 方法1:暂停运行
# time.sleep(5)
# 方式2:隐式等待
# driver.implicitly_wait(10)
# job_element_list = driver.find_elements(By.CSS_SELECTOR, ".jname.text-cut")
# 方式3:显式等待
wait = WebDriverWait(driver, timeout=10, poll_frequency=0.5)
job_element_list = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, ".jname.text-cut"))
)
duration = time.time()-start
print(f"程序等待了 {duration:.2f} 秒")
print(f"共找到 {len(job_element_list)} 个岗位")
for job_element in job_element_list:
print(job_element.text)六、用Selenium自动控制键盘
为什么要学习键盘输入
在爬虫与自动化场景中,多数网站需要模拟真实用户操作才能正常获取数据,而登录账号、填写验证码、搜索关键词、提交表单等核心操作,都依赖键盘输入完成。
基础文本输入
操作步骤:先定位输入框元素,再调用 send_keys() 方法输入内容
特殊情况:若输入框位于 frame 框架内,需先切换框架再定位操作
# 定位并切换 iframe
iframe_elem = driver.find_element(By.XPATH, "//iframe[@id='login-frame']")
driver.switch_to.frame(iframe_elem)
# 定位输入框并输入内容
username_input = driver.find_element(By.NAME, "username")
password_input = driver.find_element(By.ID, "password")
username_input.send_keys("test_user123")
password_input.send_keys("mypassword456")模拟键盘按键
需先导入 Keys 类,通过 send_keys() 搭配按键常量实现模拟按键。
常用按键:
Keys.ENTER:回车键Keys.BACKSPACE:退格键Keys.CONTROL:Windows系统Ctrl键Keys.COMMAND:Mac系统Command键
from selenium.webdriver.common.keys import Keys
# 模拟按下回车
code_element.send_keys(Keys.ENTER)键盘快捷键操作
全选:
send_keys(Keys.CONTROL + "a")复制:
send_keys(Keys.CONTROL + "c")粘贴:
send_keys(Keys.CONTROL + "v")
注意:Mac系统需用 Keys.COMMAND 替换 Keys.CONTROL
输入内容模式
追加输入(默认)
send_keys() 不会清空原有内容,直接在文本末尾追加新内容。
# 默认追加输入
search_input = driver.find_element(By.NAME, "search")
search_input.send_keys("python")
search_input.send_keys(" 教程") # 结果:python 教程覆盖输入
方法一:全选 + 删除 + 输入新内容
search_input.send_keys(Keys.CONTROL + "a")
search_input.send_keys(Keys.BACKSPACE)
search_input.send_keys("java 教程")方法二(推荐):使用clear ()清空输入框,再输入新内容(由于电脑操作系统的不同,更推荐用这种方法)
code_element.clear()
code_element.send_keys("789")七、用Selenium自动控制鼠标
什么要学习鼠标操作
网页中点击、双击、右键、悬停、拖拽等复杂交互,需要通过模拟鼠标操作实现,常用于点击按钮、拖动滑块验证码、拖拽上传文件等场景。
页面滚动操作
通过.execute_script( )执行JavaScript代码实现页面滚动,无需定位鼠标即可控制滚动效果。
按像素滚动:
driver.execute_script("window.scrollBy(横向滚动的像素数, 纵向滚动的像素数);")(正数表示向右或向下滚动,负数表示向左或向上滚动)滚动到某元素可见:
driver.execute_script("arguments[0].scrollIntoView();", 元素)(arguments[0]表示传入的第一个参数,scrollIntoView()表示让传入的元素,滚动到页面的可视区域中)
# 向下滚动300像素
driver.execute_script("window.scrollBy(0, 300);")
# 滚动至指定元素可见位置
anony_book_element = driver.find_element(By.ID, "anony-book")
driver.execute_script("arguments[0].scrollIntoView();", anony_book_element)基础鼠标点击
直接调用元素的 click() 方法,实现鼠标单击操作。
tab_account_element = driver.find_element(By.CLASS_NAME, "account-tab-account")
tab_account_element.click()高级鼠标动作(ActionChains)
需导入 ActionChains 类,遵循「实例化对象→添加动作→执行perform()」的流程完成操作。
from selenium.webdriver.common.action_chains import ActionChains
actions = ActionChains(driver) #创建实例化对象
~鼠标双击 .double_click()
actions.double_click(username_element).perform() #添加动作→执行perform()鼠标三击 .double_click().click()
actions.double_click(username_element).click(username_element).perform() #添加动作→执行perform()元素拖拽 .drag_and_drop()
# 将源元素拖拽至目标元素
actions.drag_and_drop(link_fwd_element, username_element).perform() #添加动作→执行perform()滑动验证码模拟: 按住.click_and_hold()→移动.move_by_offset(, )→松开.release()
# 按住滑块→向右移动50像素→松开鼠标
actions.click_and_hold(puzzle_piece_element).move_by_offset(50, 0).release().perform() #添加动作→执行perform()获取元素基础信息
获取元素坐标 .location
location = puzzle_piece_element.location
print(location["x"], location["y"]) #location["x"]为元素左上角的坐标,location["y"]为元素右上角的坐标获取元素尺寸 .size
size = puzzle_piece_element.size
print(size["width"], size["height"])获取元素CSS样式 .value_of_css_property()
background_image = background_element.value_of_css_property("background-image")八、总结与选型建议
简单静态页面:用requests+解析库,高效低成本
动态/反爬严格页面:用Selenium自动化,稳定可靠
大规模爬取:可结合无头模式+代理池,平衡效率与风控
Selenium的核心是模拟真人,用好等待、元素定位与交互操作,绝大多数网页数据都能轻松获取。
