
进入目标站点,搜索对应的关键词。
页面将跳转至企业信息页面,用户可以在页面底部进行分页操作,查看更多信息。
企查查采用 AJAX 请求 动态加载数据。每次翻页时,前端通过发送 AJAX 请求获取新的数据,并更新页面显示。
步骤一:识别加密
找接口
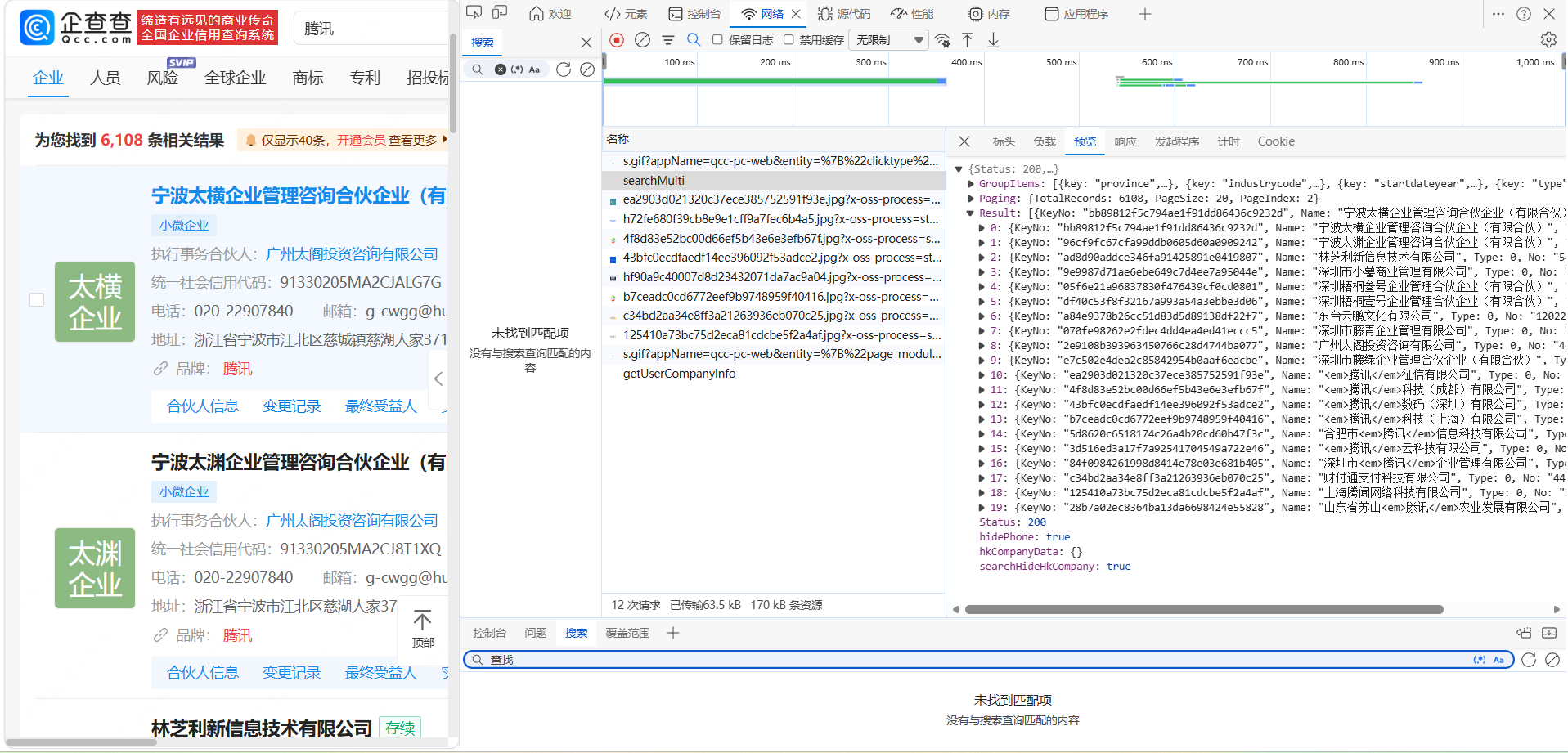
点击 searchMulti请求,展开 Result 字段,查看返回的公司信息,这些就是我们需要的爬取数据。
找参数
对比请求差异
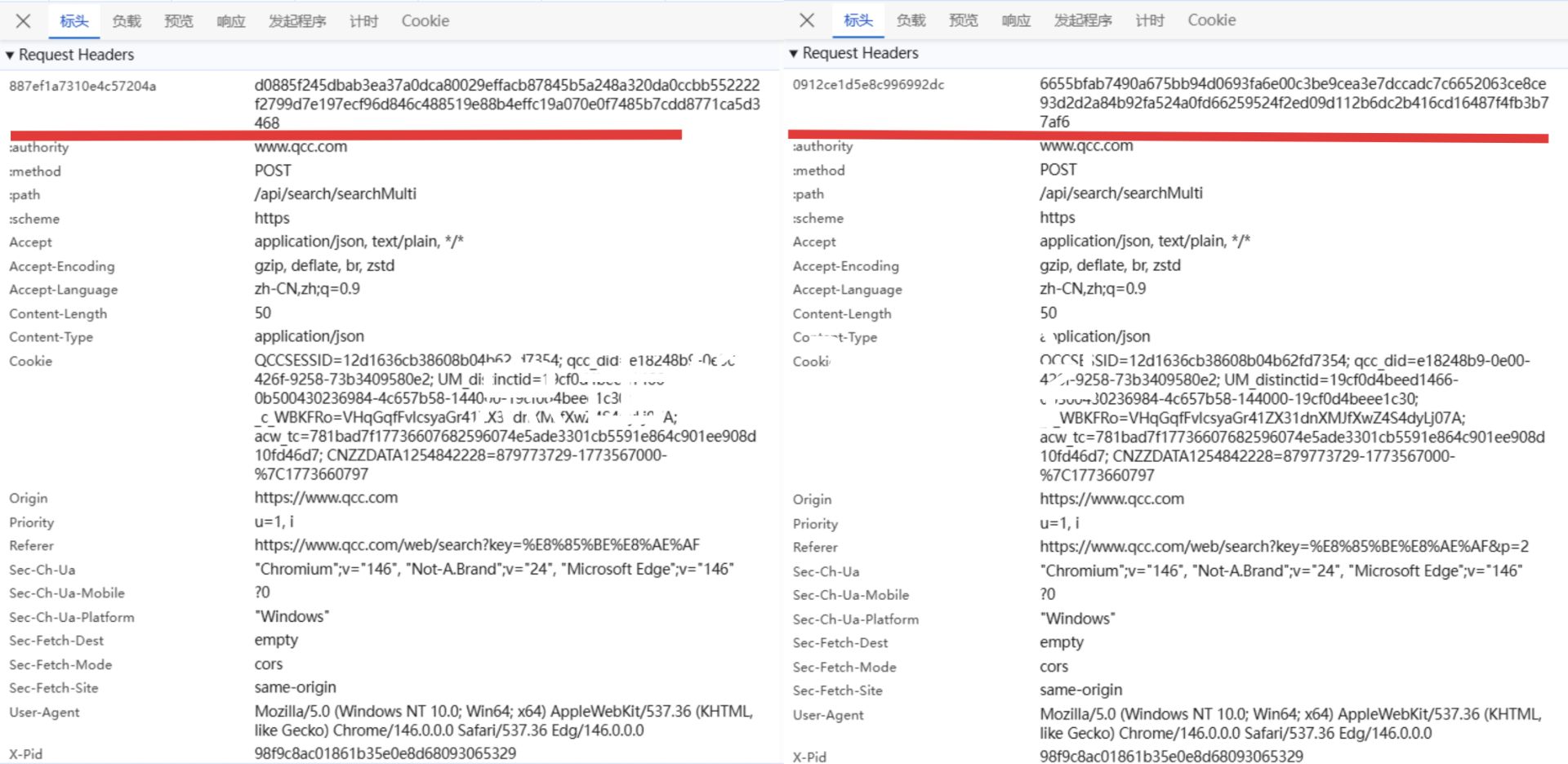
可以发现请求头中有一组动态变化的键值对。请求头中,键名如 887ef和 0912c等,键值如 d0885 和 6655b等,每次请求都会变化。
分析负载参数
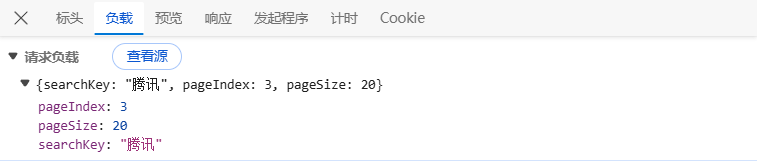
请求的负载中包含分页参数,如 pageIndex、pageSize、searchKey
结论:
需要破解的是动态生成的请求头,尤其是包含奇怪键名和键值的部分。
这些键名和值无法通过全局搜索直接找到,需要进一步通过 XHR 断点和栈追踪分析。
步骤二:参数定位
找位置
利用XHR 断点分析,追溯动态请求头的生成(具体过程略)
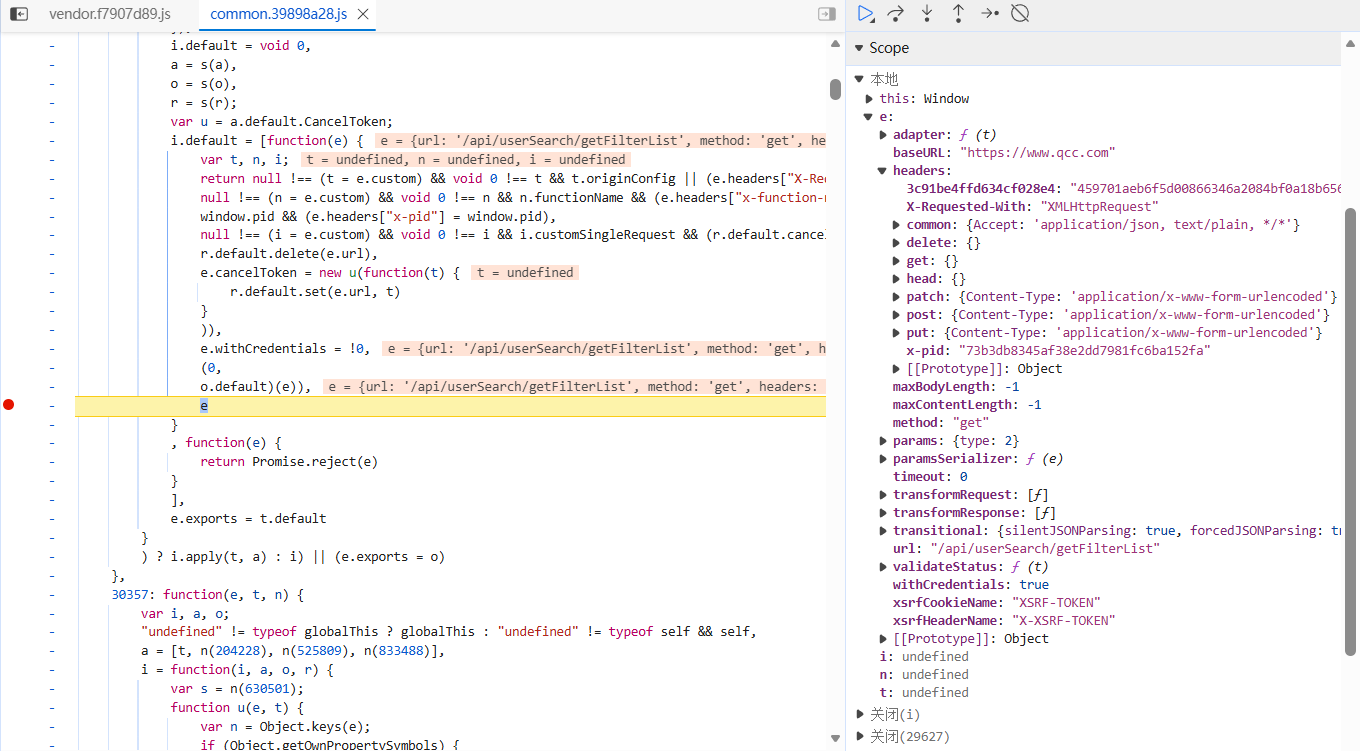
在代码执行到 o.default(e) 后,发现 e.headers 中出现了加密后的请求头。
步骤三:参数分析
找逻辑(键值对i:u的生成)
( _____ , ______)为逗号运算符:它的作用是从左到右执行表达式。
(0, o.default)(e) 会首先执行 0,然后执行 o.default 。由于 0 并不影响执行结果,这种写法实际上等价于 o.default(e)。
为什么不直接写 o.default(e)?
原因:
涉及到 JavaScript 中 this 的指向问题。
如果写成
o.default(e),那么函数中的this会绑定到o对象。使用
(0, o.default)(e),通过逗号运算符将this与o解绑,确保函数的 this 指向 全局对象,避免绑定错误。
接下来进入o.default(e) 函数里具体分析加密逻辑的核心部分
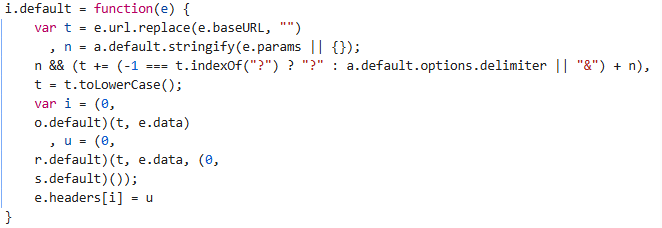
提取路径:
var t = e.url.replace(e.baseURL, "");功能:目的是将完整的请求路径中的基础域名部分去除,保留接口路径部分。
示例:
e.url = '/api/search/searchMulti'
e.baseURL = 'https://www.qcc.com'
由于 e.url 并不包含域名,替换操作对 t 的值没有影响。
参数序列化:
n = a.default.stringify(e.params || {});功能:将 e.params 转换为 URL 参数字符串。如果有额外的参数如分页、查询关键词等,它们将被添加到路径后。
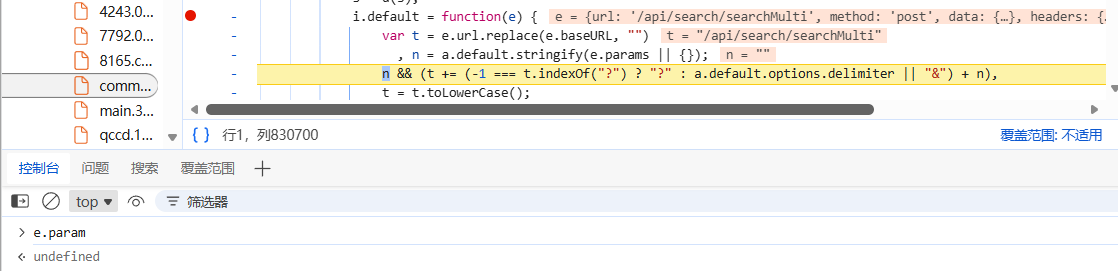
结果:e.params 为 undefined,则 n 为空字符串,拼接操作将跳过。
路径转小写:
t = t.toLowerCase();功能:将路径中的大写字母转换为小写。
结果:例如,将 /api/search/searchMulti 转为 /api/search/searchmulti。
生成和写入加密键值对:
var i = (0, o.default)(t, e.data)
, u = (0, r.default)(t, e.data, (0, s.default)());
e.headers[i] = u;功能:将生成的加密键值对写入到请求头中。
结果:请求头中的键值对现在包含了由 o.default 和 r.default 生成的加密参数。
参数名 i 的生成逻辑
i = (0, o.default)(t, e.data)参数解析:
t是接口路径,固定值:'/api/search/searchmulti'。e.data是请求负载参数,即我们在发起请求时发送的数据。
跳转到 o.default 方法的内部实现,来看它是如何处理传入的参数的

var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {} ;
var t = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase()它的作用是做一个参数合法性判断
e: 如果传入了第二个参数,它会被赋值给 e;否则,e 默认为空对象 {}。
即 e = e.data={"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}
t: 第一个参数 t 是接口路径。如果没有传入,默认为 '/',并转换成小写。
即 t = '/api/search/searchmulti';
n = JSON.stringify(e).toLowerCase();n: 将 e(即请求负载)转换成小写的 JSON 字符串:
即 n='{"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}'
return (0,
a.default)(t + n, (0,
o.default)(t)).toLowerCase().substr(8, 20)代码可简化为 a.default(t + n, o.default(t)).toLowerCase().substr(8, 20)
解析a.default:
第一个参数t+n:
t + n = '/api/search/searchmulti{"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}'第二个参数o.default(t):
(0,o.default):i.default = function() {
for (var e = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(), t = e + e, n = "", i = 0; i < t.length; ++i) {
var o = t[i].charCodeAt() % a.default.n;
n += a.default.codes[o]
}
return n
}
该函数先获取传入的首个参数(无则默认 "/")并转为小写,将其拼接成原字符串 2 倍长度的新字符串;随后遍历该新字符串的每个字符,取字符 ASCII 码对预设数字a.default.n取模,用得到的索引从预设字符数组a.default.codes中取值,拼接所有取值结果后返回。
输入固定(比如接口路径是
'/api/search/searchmulti')→ 转小写后仍固定 → 拼接成t+t也固定;遍历每个字符时,
charCodeAt()是固定值(每个字符的 ASCII 码唯一);a.default.n和a.default.codes是预设的固定值(只要这两个值不变);取模和数组取值的结果也完全固定 → 最终拼接的字符串必然固定。
因此,o.default(t)是一个固定字符串'iLAgiklLN8QiklLN8QrLi4giLAgiklLN8QiklLN8QrLi4g'
最终拼接与加密:
将拼接后的字符串 t + n 和固定字符串 (0, o.default)(t) 传入 a.default 方法进行处理。
进入a.default 方法

打上断点让网页执行到这一步,再次点击进去a.default 方法内部



从对象结构能看出的细节
sigBytes: 64:说明使用的是 SHA-512 哈希算法(SHA-512 输出 64 字节,即 512 位)。words: Array(16):WordArray 内部用 32 位整数数组存储数据,64 字节 = 16 × 32 位,符合 SHA-512 的输出长度。$super、init等方法:这是典型的 CryptoJS 类库结构(CryptoJS 是前端常用的加密库,HMAC-SHA 系列是其核心功能)。
结论
这是 HMAC-SHA512 签名:从
sigBytes: 64可确定哈希算法是 SHA-512,整体是 HMAC-SHA512 签名流程。输出是固定长度的十六进制签名字符串:最终
.toString()得到的是 128 个十六进制字符(64 字节),只要输入的t(密钥)、n(算法)、e(数据)固定,签名结果就完全固定。库来源大概率是 CryptoJS:对象结构(
words、sigBytes、原型方法)和 API 风格(init/finalize/toString)都和 CryptoJS 高度一致。
密钥n:'iLAgiLklNklLN8QiBl4kgi4lNigk4B4lAllviLAgiLklNklLN8QiBl4kgi4lNigk4B4lAllv'
明文e:'/api/search/searchmulti{"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}'
加密参数名 i 就是 HMAC-SHA512 结果的处理结果, 加密结果转换为小写。截取加密结果的第 9 个字符开始的 20 个字符,得到最终的请求参数名 i。
参数名 u的生成逻辑
u = (0, r.default)(t, e.data, (0, s.default)())代码可简化为u =r.default(t, e.data, s.default())
参数解析:
t是接口路径,固定值:'/api/search/searchmulti'。e.data是请求负载参数,即我们在发起请求时发送的数据。即{"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}s.default:接下来跳转到的内部实现

这段代码是典型的字符串混淆写法:
把完整代码拆成单个字符存入数组,避免直接暴露敏感代码(比如这里的 window.tid)。运行时通过 join() 还原字符串,再用 eval() 执行,本质就是返回 window.tid 。

因此,(0,s.default)() 的值为window.id,即固定的字符串'5b57835becb264c135d5245777469061'
三个参数准备完毕,最后回到r.default 方法的实现中
变量赋值:
var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {},
t = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : "",
n = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(),
i = JSON.stringify(e).toLowerCase();e:如果存在第二个参数,则使用该参数,否则默认为一个空对象 {}。
即e = e.data={"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}
t:如果存在第三个参数,则使用该参数,否则默认为空字符串 ""
即t = (0,s.default)() = eval(window.tid) = '5b57835becb264c135d5245777469061'
n:如果传入了第一个参数,则使用该参数,并将其字符串全部转换为小写,否则默认为 '/'。
即n = t = '/api/search/searchmulti'
i:这是请求负载参数 e 转换为 JSON 字符串后,再将所有字符转为小写格式。
即 i = e = '{"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}'
拼接与加密
return (0,a.default)(n + "pathString" + i + t, (0,o.default)(n))代码可简化为 return a.default(n + "pathString" + i + t, o.default(n))
解析a.default:
第一个参数n + "pathString" + i + t :
'/api/search/searchmultipathString{"searchkey":"腾讯","pageindex":2,"pagesize":20}5b57835becb264c135d5245777469061'
第二个参数(0,o.default)(n) :
进入o.default() 里分析
i.default = function() {
for (var e = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(), t = e + e, n = "", i = 0; i < t.length; ++i) {
var o = t[i].charCodeAt() % a.default.n;
n += a.default.codes[o]
}
return n
}此前已经分析过o.default(t)是一个固定字符串'iLAgiLklNklLN8QiBl4kgi4lNigk4B4lAllviLAgiLklNklLN8QiBl4kgi4lNigk4B4lAllv'
将两个生成的参数传入 a.default 方法进行加密:


密钥:'/api/search/searchmultipathString{"searchkey":"腾讯","pageindex":2,"pagesize":20}5b57835becb264c135d5245777469061'
明文:'/api/search/searchmulti{"searchKey": "腾讯","pageIndex": 2,"pageSize": 20}'
加密参数名 u 就是 HMAC-SHA512 结果的处理结果
步骤四:参数调用
把加密函数及其调用逻辑封装成一个可调用函数(JS 文件内)
let CryptoJS = require("crypto-js");
function get_headers(searchKey,pageIndex){
const e = JSON.stringify({"searchKey":searchKey ,"pageIndex": pageIndex,"pageSize": 20}).toLowerCase(),
key = 'iLAgiLklNklLN8QiBl4kgi4lNigk4B4lAllviLAgiLklNklLN8QiBl4kgi4lNigk4B4lAllv',
url = '/api/search/searchmulti',
tid = '5b57835becb264c135d5245777469061',
data1 = url + e,
data2 = url + "pathString" + e + tid,
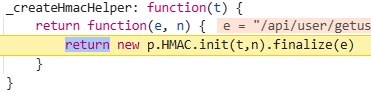
i = CryptoJS.HmacSHA512(data1, key).toString().substr(8,20);
u = CryptoJS.HmacSHA512(data2, key).toString();
return [i,u];
}
//console.log(get_headers('腾讯',2));在 Python 中用 execjs 调用该函数得到加密参数的值
# 导入第三方库:requests用于发送HTTP请求,execjs用于执行JavaScript代码
import requests
import execjs
def get_data(searchKey, pageIndex):
"""
调用企查查搜索接口,获取企业搜索结果数据
:param searchKey: 要搜索的企业关键词(如"腾讯")
:param pageIndex: 搜索结果的页码(从1开始)
:return: 接口返回的JSON数据,请求失败则返回None
"""
# TODO: 由于Cookies具有时效性,需定期将Cookie替换为浏览器中最新的有效Cookie
cookies = {
'QCCSESSID': '12d1636cb38608b04b62fd7354',
'qcc_did': 'e18248b9-0e00-426f-9258-73b3409580e2',
'UM_distinctid': '19cf0d4beed1466-0b500430236984-4c657b58-144000-19cf0d4beee1c30',
'_c_WBKFRo': 'VHqGqfFvIcsyaGr41ZX31dnXMJfXwZ4S4dyLj07A',
'acw_tc': '781bad3917738244885214300ef2a4f84df04d3fa2a2666f73f63d4815b197',
'CNZZDATA1254842228': '879773729-1773567000-%7C1773824496',
}
# HTTP请求头,模拟浏览器行为,包含反爬校验字段
headers = {
'887ef1a7310e4c57204a': 'd0885f245dbab3ea37a0dca80029effacb87845b5a248a320da0ccbb552222f2799d7e197ecf96d846c488519e88b4effc19a070e0f7485b7cdd8771ca5d3468',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9',
'content-type': 'application/json',
'origin': 'https://www.qcc.com',
'priority': 'u=1, i',
'referer': 'https://www.qcc.com/web/search?key=%E8%85%BE%E8%AE%AF',
'sec-ch-ua': '"Chromium";v="146", "Not-A.Brand";v="24", "Microsoft Edge";v="146"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/146.0.0.0 Safari/537.36 Edg/146.0.0.0',
'x-pid': '3bd88ed4e4d72bc10dbe5cde7dda722d',
'x-requested-with': 'XMLHttpRequest',
# 'cookie': '...' 已通过cookies参数传递,此处注释避免重复
}
# POST请求的JSON数据体,包含搜索关键词和分页参数
json_data = {
'searchKey': searchKey,
'pageIndex': pageIndex,
'pageSize': 20, # 每页返回20条结果
}
# 读取本地JS加密脚本文件
with open('qichacha.js', 'r', encoding='utf-8') as f:
js_code = f.read()
# 编译JS代码为可执行环境
js = execjs.compile(js_code)
# 调用JS函数get_headers,生成动态校验参数i和u
q = js.call('get_headers', searchKey, pageIndex)
i = q[0] # 动态参数名(如加密后的header键)
u = q[1] # 动态参数值
# 将动态校验参数添加到请求头中,完成反爬校验
headers[i] = u
try:
# 发送POST请求到企查查搜索接口
response = requests.post(
'https://www.qcc.com/api/search/searchMulti',
cookies=cookies,
headers=headers,
json=json_data
)
# 主动抛出HTTP状态码异常(如404、500等)
response.raise_for_status()
# 解析并返回接口返回的JSON数据
return response.json()
except requests.exceptions.RequestException as e:
# 捕获所有网络请求相关异常(连接失败、超时、HTTP错误等)
print(f"请求失败: {e}")
return None
except Exception as e:
# 捕获其他未知异常(如JS执行错误、JSON解析错误等)
print(f"其他错误: {e}")
return None
if __name__ == '__main__':
# 主程序入口:测试调用get_data函数
searchKey = '腾讯' # 搜索关键词
pageIndex = 2 # 要查询的页码
result = get_data(searchKey, pageIndex)
# 打印接口返回结果
print(result)